|
|
敢为人先 优酷土豆用Spark完善大数据分析优酷土豆作为国内最大的视频网站,和国内其他互联网巨头一样,率先看到大数据对公司业务的价值,早在2009年就开始使用Hadoop集群,随着这些年业务迅猛发展,优酷土豆又率先尝试了仍处于大数据前沿领域的Spark/Shark 内存计算框架,很好地解决了机器学习和图计算多次迭代的瓶颈问题,使得公司大数据分析更加完善。 大数据,一个似乎已经被媒体传播的过于泛滥的词汇,的的确确又在逐渐影响和改变着我们的生活。也许有人认为大数据在中国仍然只是噱头,但在当前中国互联网领域,大数据以及大数据所催生出来的生产力正在潜移默化地推动业务发展,并为广大中国网民提供更加优秀的服务。优酷土豆作为国内最大的视频网站,和国内其他互联网巨头一样,率先看到大数据对公司业务的价值,早在2009年就开始使用Hadoop集群,随着这些年业务迅猛发展,优酷土豆又率先尝试了仍处于大数据前沿领域的Spark/Shark内存计算框架,很好地解决了机器学习和图计算多次迭代的瓶颈问题,使得公司大数据分析更加完善。 MapReduce之痛 提到大数据,自然不能不提Hadoop。HDFS已然成为大数据公认的存储,而MapReduce作为其搭配的数据处理框架在大数据发展的早期表现出了重大的价值。可由于其设计上的约束MapReduce只适合处理离线计算,其在实时性上仍有较大的不足,随着业务的发展,业界对实时性和准确性有更多的需求,很明显单纯依靠MapReduce框架已经不能满足业务的需求了。 优酷土豆集团大数据团队技术总监卢学裕就表示:“现在我们使用Hadoop处理一些问题诸如迭代式计算,每次对磁盘和网络的开销相当大。尤其每一次迭代计算都将结果要写到磁盘再读回来,另外计算的中间结果还需要三个备份,这其实是浪费。” 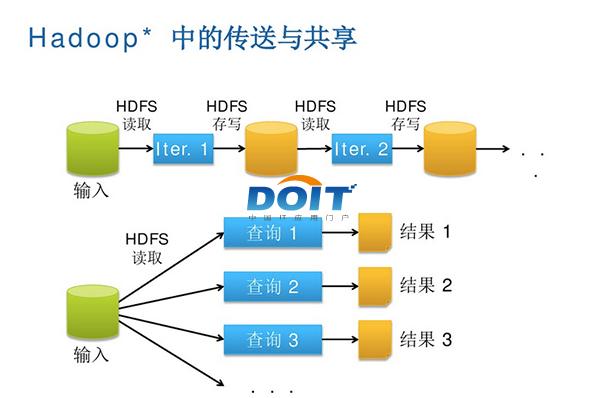 图一:Hadoop中的数据传送与共享,串行方式、复制以及磁盘IO等因素, 使得Hadoop集群在低延迟、实时计算方面表现有待改进。 据悉,优酷土豆的Hadoop大数据平台是从2009年开始采用,最初只有10多个节点,2012年集群节点达到150个,2013年更是达到300个,每天处理数据量达到200TB。优酷土豆鉴于Hadoop集群已经逐渐胜任不了一些应用,于是决定引入Spark/Shark内存计算框架,以此来满足图计算迭代等的需求。 Spark是一个通用的并行计算框架,由伯克利大学的AMP实验室开发,Spark已经成为继Hadoop之后又一大热门开源项目,目前已经有英特尔等企业加入到该开源项目。 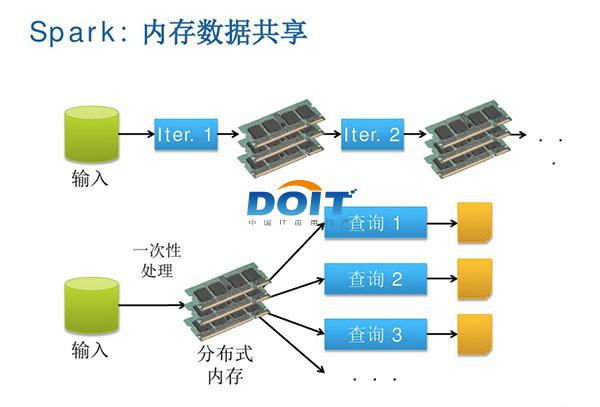 图二:Spark内存计算框架使得数据共享比网络和磁盘快10倍到100倍。 责编:郑雄  微信扫一扫实时了解行业动态 微信扫一扫实时了解行业动态 著作权声明:kaiyun体育官方人口
文章著作权分属kaiyun体育官方人口
、网友和合作伙伴,部分非原创文章作者信息可能有所缺失,如需补充或修改请与我们联系,工作人员会在1个工作日内配合处理。 |
最新专题 |

|
|

