
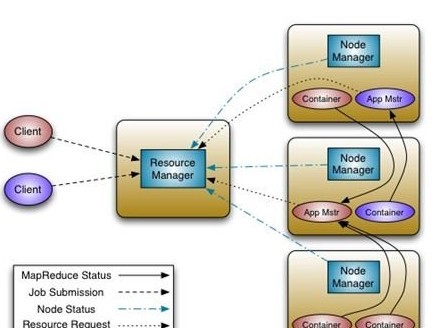
为解瓶颈雅虎欲重构Hadoop-MapReduce最近雅虎开发者博客发了一篇介绍Hadoop重构计划的文章。因为他们发现当集群的规模达到4000台机器的时候,Hadoop遭遇到扩展性的瓶颈,目前他们正准备开始对Hadoop进行重构。 最近雅虎开发者博客发了一篇介绍Hadoop重构计划的文章。因为他们发现当集群的规模达到4000台机器的时候,Hadoop遭遇到扩展性的瓶颈,目前他们正准备开始对Hadoop进行重构。 Mapreduce面临的瓶颈 从集群大小和工作量中观察到的趋势是,MapReduce的JobTracker需要彻底改革,以解决其可扩展性,内存消耗,线程模型,可靠性和性能的几个缺陷。Mapreduce在过去5年框架不断的修复过程中发现成本在不断增加。目前Hadoop各个模块的紧耦合使得在现有设计的基础上继续改进变得举步维艰。这一点早已在社区内达成共识,所以他们正准备开始对Hadoop进行重构。不过从操作的角度来看,任何轻微的或修复Bug带来的巨大改动都会让Hadoop MapReduce强制进行全系统的升级。 下一代MapReduce构思 据该博客文章表示,新架构的主要思想是把原来JobTracker的功能一分为二:ResourceManager管理资源的分配,ApplicationMaster管理任务监控和调度。ResourceManager与原有的JobTracker类似,作为整个集群的控制中心;而ApplicationMaster则是每个application都有一个单独的实例,application是用户提交的一组任务,它可以由一个或多个job组成。每台slave运行一个NodeManager实例,功能类似于原来的TaskTracker。
1.层次化的管理 目前Hadoop的资源管理和任务调度都是在JobTracker中进行的,它需要复制所有task的资源分配和调度。而task是非常微观的调度单位,通常每个job都会产生成百上千个task,而系统同一时刻又会有大量的job同时运行,这让JobTracker的管理负担变得非常繁重。新架构将这一管理任务下放到各个ApplicationMaster,ResourceManager只管理每个application的资源分配。这样即使系统中存在很多application,ResourceManager的负担也能控制在一个合理的程度;这也是新架构最大的优势。 2.ApplicationMaster应该在Master还是Slave上运行? 新架构实际上将管理和调度的任务转移到ApplicationMaster上来,如果ApplicationMaster所在的节点挂掉,整个任务都需要重做。原来JobTracker可以跑在相对稳定的Master上,出错概率低;现在ApplicationMaster跑在好些Slave上,出错的概率就非常高了。而且新架构打破了原来简单的Master-Slave模型,节点之间的通讯和依赖关系变得更加复杂,增加了网络优化的难度。如果把ApplicationMaster全都放在Master上执行,则Master的负担会非常重(需要处理各种持续性的heartbeat和爆发性的如getTaskCompletionEvents这样的rpc请求),不过这个问题可以通过分布式的Master解决(Google已经实现)。 3.资源管理方式 原来单纯地以简单静态的slot作为资源单位确实不能很好描述集群的资源状况。新架构将更细粒度地控制CPU,内存,磁盘,网络这些资源。每个task都将在Container中执行,并只能使用其所分配到的系统资源。资源的分配可以用静态估计动态调整的方式实现。 4.支持其他编程模型 由于任务的管理和调度都由ApplicationMaster进行,ApplicationMaster又相对独立于系统的其他模块,用户甚至可以部署自己的ApplicationMaster,实现对其他编程模型的支持。这使得其他不大适合用MapReduce实现的应用程序也能在同一个Hadoop集群中运行。 可伸缩性实现 可伸缩性对当前的硬件发展趋势是非常重要的,目前MapReduce集群已经有4000台主机。然而2009年的集群中的4000台主机(8核,16GB内存,4TB存储)只有2011年集群中4000台主机(16核,48GB内存,24TB存储)一半的处理能力。此外,考虑到运营成本,迫使集群中运行6000台主机,以后可能会更多。 可用性实现 ResourceManager —— ResourceManager使用Apache的ZooKeeper实现故障转移。当ResourceManager失败时,可以通过Apache的ZooKeeper迅速恢复集群状态。在故障转移后,所有队列运行的应用程序都会重新启动。 ApplicationMaster —— MapReduce的NextGen支持为ApplicationMaster应用进行特定的检查。MapReduce的ApplicationMaster可以从失败中恢复,通过自身恢复到HDFS保存的状态。 兼容性实现 MapReduce的NextGen使用Wire-兼容协议(wire-compatible protocols)来允许不同版本的服务器和客户端进行信息交换。在未来的版本中,这一特性将一直保留,以保证集群升级后仍然兼容。 集群实现 MapReduce NextGen Resource使用常规的概念调度并将资源分配给各个应用程序。集群中的每台机器概念上都是由资源组成的,如内存,I/O带宽等。 支持其他的编程模型 MapReduce的NextGen提供了一个完全通用的计算框架,以支持MapReduce和其他范例。 该架构最终允许用户能够实现自定义ApplicationMaster,它可以要求ResourceManager的资源利用他们。因此,它支持多种编程,如MapReduce,MPI,Master-Worker以及Iterative models在Hadoop上。并允许为每个应用使用适当的框架。这对于应用程序(如K-Means, Page-Rank)在自定义框架外运行MapReduce。 结论 Apache的Hadoop,特别是Hadoop的MapReduce是一个非常成功的开源的处理大数据集的项目。我们建议Hadoop的MapReduce提高可用性、提高集群使用,并提供范式的编程架构以及 实现快速的发展。Yahoo将和Apache基金会一起将Hadoop在处理大数据的能力提高到一个新水平。 责编:张泽牧  微信扫一扫实时了解行业动态 微信扫一扫实时了解行业动态 著作权声明:kaiyun体育官方人口
文章著作权分属kaiyun体育官方人口
、网友和合作伙伴,部分非原创文章作者信息可能有所缺失,如需补充或修改请与我们联系,工作人员会在1个工作日内配合处理。 |
最新专题 推荐圈子 |



|
|

