
海量结构化数据存储检索系统
Big Data是近年在云计算领域提出的对数据的加载效率、存储规模以及数据的检索效率有很高要求的应用场合,通常数据的加载效率在Mb/s甚至Gb/s量级,数据的存储规模在TB甚至PB规模,本文称这种模式为“大数据集”管理。大数据集的一类重要应用针对结构化数据的存储与检索
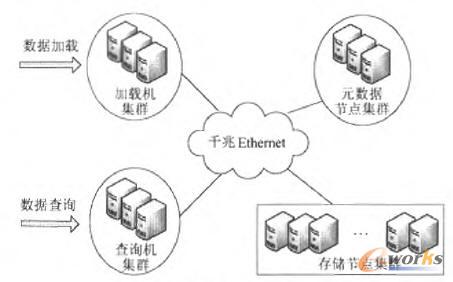
Big Data是近年在云计算领域提出的对数据的加载效率、存储规模以及数据的检索效率有很高要求的应用场合,通常数据的加载效率在Mb/s甚至Gb/s量级,数据的存储规模在TB甚至PB规模,本文称这种模式为“大数据集”管理。大数据集的一类重要应用针对结构化数据的存储与检索。典型的应用如海量日志、网络报文以及web2,0框架下的SNS,电子商务,数据挖掘等应用场合。传统的RDBMS由于数据一致性的约束,在管理大规模数据集存储条件下,在数据更新、局部数据失效以及系统扩展性等方面工作效率低下。目前的解决思路是:通过放宽对于数据一致性的要求,取消复杂的关联查询,结合具体的应用场景,提高系统的可用性。但是由于大量的记录存放于同一个表空间中,会达到数十亿条甚至上百亿条记录的规模。在如此大规模数据存储条件下,如何高效的实现数据的存储、检索都面临着新的挑战。 Google对这一问题进行深入分析,结合Google的业务背景,提出Bigtable数据管理方法,建立列存储数据结构,提供基于Row-Key的数据检索接口。此后,业界也纷纷提出分布式结构化数据存储管理模型,也称为No-SQL(Not Only Sql)数据库。典型的No-SQL数据库包括Dynamo,Cassandra, PNUTS,Hbase以及Hypertable等:但是目前的海量结构化数据管理系统对于数据检索的多属性支持较弱,通常仅提供基于Key的读取GET和写入PUT操作,不具备多属性查询,数值统计、分析等复杂的查询功能。 目前基于Hadoop提出的数据仓库工具HIVE、PIG等,可以支持复杂的查询条件,但是不适用于流数据的高效存储与检索。如HIVE仅支持文本文件的批量导入,不支持流数据在线频繁加载操作。在复杂条件的检索过程中HIVE会把查询条件分解成多个MapReduce任务,每个Map过程以及Reduce结果都要把文件写入到集群文件系统中进行缓存,导致系统检索效率低,不适用于流数据的高效存储与查询。 针对该问题,本文基于Hadoop建立面向结构化流数据提出具有在线数据加载和快速检索的分布式数据存储系统MDSS(Massive Data Storage System),建立二维表空间数据管理模型,重点解决数据的分布存储与复杂条件的快速查询问题。 1 MDSS系统工作原理 “大数据集”要求较高的数据加载效率、数据存储效率以及数据检索效率,目前主要的解决思路是利用多机协同的分布式存储环境提高系统的处理效率。MDSS分布式系统结构如图1所示,系统包括三个部分:加载机集群、查询机集群、元数据节点集群以及存储节点集群。
图1 MDSS系统结构图 加载机集群:整个系统的数据加载端。可以以进程为单位,在多台设备上同时建立多个并发数据加载客户端,通过并发加载提高系统整体加载效率。在MDSS中,加载机集群同时缓存近期入库的数据,经过固定的时间周期,把缓存数据通过Gb Ethernet写到数据存储管理装置中。 查询机集群:用户在查询机上发出查询指令,查询机根据元数据节点集群保存的元数据信息,向存储节点分发查询任务,最后汇总多个存储节点返回的查询结果,提交给用户; 存储节点集群:持久存储长期保存的历史数据。把数据源进行分块存储,通常把一次或几次从加载机刷新到集群中的数据作为数据分块。
责编:chrislee2012
 微信扫一扫实时了解行业动态
微信扫一扫实时了解行业动态
著作权声明:kaiyun体育官方人口 文章著作权分属kaiyun体育官方人口 、网友和合作伙伴,部分非原创文章作者信息可能有所缺失,如需补充或修改请与我们联系,工作人员会在1个工作日内配合处理。
|
最新专题
推荐圈子
|



|
|

