|
|
敢为人先 优酷土豆用Spark完善大数据分析优酷土豆作为国内最大的视频网站,和国内其他互联网巨头一样,率先看到大数据对公司业务的价值,早在2009年就开始使用Hadoop集群,随着这些年业务迅猛发展,优酷土豆又率先尝试了仍处于大数据前沿领域的Spark/Shark 内存计算框架,很好地解决了机器学习和图计算多次迭代的瓶颈问题,使得公司大数据分析更加完善。 用Spark/Shark完善大数据分析 目前大数据在互联网公司主要应用在广告、报表、推荐系统等业务上。在广告业务方面需要大数据做应用分析、效果分析、定向优化等,在推荐系统方面则需要大数据优化相关排名、个性化推荐以及热点点击分析等。优酷土豆属于典型的互联网公司,目前运用大数据分析平台的主要工作是运营分析、机器学习、广告定向优化、搜索优化等方面。 优酷土豆集团大数据团队技术总监卢学裕表示:“优酷土豆的大数据平台已经用了很多年,突出问题主要包括:第一是商业智能BI方面,公司的分析师提交任务之后需要等待很久才得到结果;第二就是大数据量计算,比如进行一些模拟广告投放之时,计算量非常大的同时对效率要求也比较高,用Hadoop消耗资源非常大而且响应比较慢;最后就是机器学习和图计算的迭代运算也是需要耗费大量资源且速度很慢。” 因此,面对复杂任务、交互式查询以及流在线处理时,Hadoop与MapReduce并不适用。Spark/Shark这种内存型计算框架则比较适合各种迭代算法和交互式数据分析,可每次将弹性分布式数据集(RDD)操作之后的结果存入内存中,下次操作可直接从内存中读取,省去了大量的磁盘IO,效率也随之大幅提升。优酷土豆集团大数据团队大数据平台架构师傅杰表示:“一些应用场景并不适合在MapReduce里面去处理。通过对比,我们发现Spark性能比MapReduce提升很多。”  图三:Spark/Shark内存计算框架实时日志聚合处理。 “比如在图计算方面,视频与视频之间存在的相似关系,这就构成了一个图谱,通过图谱来做聚类,再给用户做视频推荐。”优酷土豆集团大数据团队技术总监卢学裕表示。 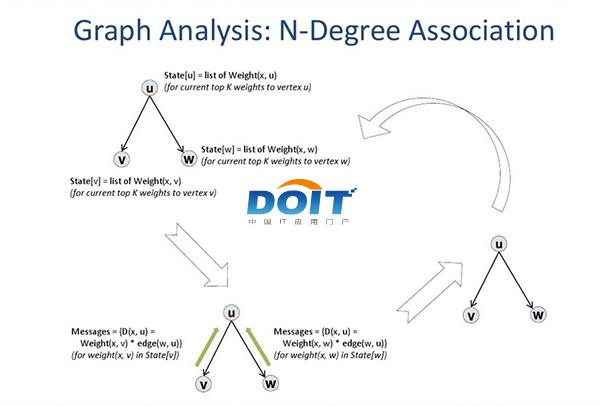 图四:图计算分析N度关联算法示意图。 优酷土豆集团大数据团队技术总监卢学裕表示:“我们进行过图计算方面的测试,在4台节点的Spark集群上用时只有5.6分钟,而同规模的数据量,单机实现需要80多分钟,并且内存吃满,单机无法实现Scale-Out,不能计算更大规模数据。” “在今天,数据处理要求非常快。比如优酷土豆的一些客户、广告商往往临时就需要看一下投放效果。所以在前端应用不变的情况下,如果能更快的响应市场的需要就变得很有竞争力。市场是瞬息万变的,有一些分析结果也需要快速响应成一个产品,Spark集成到数据平台正能发挥这样的效果。”优酷土豆集团大数据团队大数据平台架构师傅杰补充道。 据了解,优酷土豆采用Spark/Shark大数据计算框架得到了英特尔公司的帮助,起初优酷土豆并不熟悉Spark以及Scala语言,英特尔帮助优酷土豆设计出具体符合业务需求的解决方案,并协助优酷土豆实现了该方案。此外,英特尔还给优酷土豆的大数据团队进行了Scala语言、Spark的培训等。 “优酷土豆作为国内视频行业第一家商用部署Spark/Shark方案的公司,从视频行业的多样化分析角度来看是个非常好的方案。未来,英特尔将会继续与优酷土豆在Spark/Shark进行合作,包括硬件配置的优化以及整体方案的优化等”英特尔(中国)有限公司销售市场部互联网及媒体行业企业客户经理李志辉介绍道。 责编:郑雄  微信扫一扫实时了解行业动态 微信扫一扫实时了解行业动态 著作权声明:kaiyun体育官方人口
文章著作权分属kaiyun体育官方人口
、网友和合作伙伴,部分非原创文章作者信息可能有所缺失,如需补充或修改请与我们联系,工作人员会在1个工作日内配合处理。 |
最新专题 |

|
|

