Hadoop白皮书:分布式文件系统HDFS简介
Hadoop 分布式文件系统 (HDFS) 是运行在通用硬件上的分布式文件系统。HDFS 提供了一个高度容错性和高吞吐量的海量数据存储解决方案。
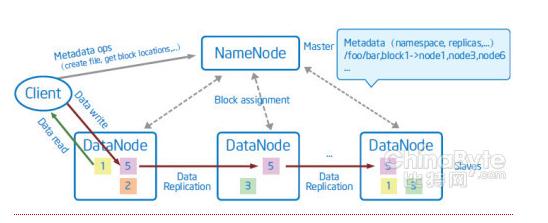
Hadoop 分布式文件系统 (HDFS) 是运行在通用硬件上的分布式文件系统。HDFS 提供了一个高度容错性和高吞吐量的海量数据存储解决方案。HDFS 已经在各种大型在线服务和大型存储系统中得到广泛应用,已经成为各大网站等在线服务公司的海量存储事实标准,多年来为网站客户提供了可靠高效的服务。 随着信息系统的快速发展,海量的信息需要可靠存储的同时,还能被大量的使用者快速地访问。传统的存储方案已经从构架上越来越难以适应近几年来的信息系统业务的飞速发展,成为了业务发展的瓶颈和障碍。 HDFS 通过一个高效的分布式算法,将数据的访问和存储分布在大量服务器之中,在可靠地多备份存储的同时还能将访问分布在集群中的各个服务器之上,是传统存储构架的一个颠覆性的发展。HDFS 可以提供以下特性: • 可自我修复的分布式文件存储系统 • 高可扩展性,无需停机动态扩容 • 高可靠性,数据自动检测和复制 • 高吞吐量访问,消除访问瓶颈 • 使用低成本存储和服务器构建 分布式文件系统 HDFS 特性 高吞吐量访问 HDFS 的每个数据块分布在不同机架的一组服务器之上,在用户访问时,HDFS 将会计算使用网络最近的和访问量最小的服务器给用户提供访问。由于数据块的每个复制拷贝都能提供给用户访问,而不是从单数据源读取,HDFS 对于单数据块的访问将是传统存储方案的数倍。 对于一个较大的文件,HDFS 将文件的不同部分存放于不同服务器之上。在访问大型文件时,系统可以并行从服务器阵列中的多个服务器并行读入,增加了大文件读入的访问带宽。 通过以上实现,HDFS 通过分布式计算的算法,将数据访问均摊到服务器阵列中的每个服务器的多个数据拷贝之上,单个硬盘或服务器的吞吐量限制都可以数倍甚至数百倍的突破,提供了极高的数据吞吐量。
无缝容量扩充 HDFS 将文件的数据块分配信息存放在NameNode 服务器之上,文件数据块的信息分布地存放在 DataNode 服务器上。当整个系统容量需要扩充时,只需要增加DataNode 的数量,系统会自动地实时将新的服务器匹配进整体阵列之中。之后,文件的分布算法会将数据块搬迁到新的DataNode 之中,不需任何系统宕机维护或人工干预。通过以上实现,HDFS 可以做到在不停止服务的情况下实时地加入新的服务器作为分布式文件系统的容量升级,不需要人工干预文件的重新分布。 高度容错 HDFS 文件系统假设系统故障(服务器、网络、存储故障等)是常态,而不是异常。因此通过多方面保证数据的可靠性。数据在写入时被复制多份,并且可以通过用户自定义的复制策略分布到物理位置不同的服务器上;数据在读写时将自动进行数据的校验,一旦发现数据校验错误将重新进行复制;HDFS 系统在后台自动连续的检测数据的一致性,并维持数据的副本数量在指定的复制水平上。
责编:杨雪姣
 微信扫一扫实时了解行业动态
微信扫一扫实时了解行业动态
著作权声明:kaiyun体育官方人口 文章著作权分属kaiyun体育官方人口 、网友和合作伙伴,部分非原创文章作者信息可能有所缺失,如需补充或修改请与我们联系,工作人员会在1个工作日内配合处理。
|
最新文章
|