|
|
数据控使用Hadoop的三种最常用方式
Hadoop保留它典型的“大数据”基础技术,但它是否适合当下数据库及数据仓库的使用方式?又是否有一种通用模式可以切实降低固有的使用复杂性。
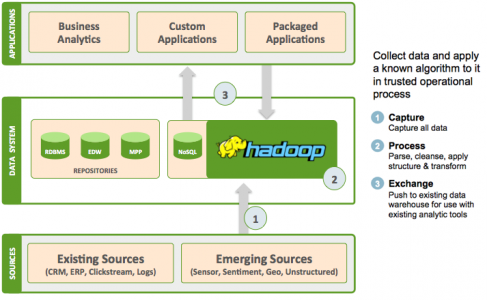
就在几周前,Apache Hadoop 2.0正式发布,这是 Hadoop领域巨大的里程碑,因为它开启了史无前例的数据存储方式革命。Hadoop保留它典型的“大数据”基础技术,但它是否适合当下数据库及数据仓库的使用方式?又是否有一种通用模式可以切实降低固有的使用复杂性呢? Hadoop使用的一般模式 Hadoop最初的构想是为像Yahoo、Google、Facebook等这样的公司以非常低的成本来解决大量数据的存储问题。现在,它正被越来越多地引入企业环境中处理新不同数据类型。机器生成的数据、传感器数据、社交数据、网络日志等数据类型呈指数级增长,而且这些数据也常常(但不总是)是非结构化。正是由于这种类型的数据将人机对话从“数据分析”带到“大数据分析”:因为挖掘这些数据可以得到商业优势。 分析应用程序以各种形式流行起来,最重要的是可以定向解决一个垂直行业的需要。乍一看,他们彼此似乎在行业和垂直上没有关系,但是实际上,当在基础设施层面观察时,会出现一些非常清晰的模式,也就是以下3种模式: Pattern 1:数据精炼厂 使用Hadoop的“数据精炼厂”模式使组织能够将这些新数据源纳入他们常用BI和分析应用程序。例如,我可能有一个应用程序,它能够在ERP和CRM系统中查看客户建立在上面的数据。但是如何才能从他们的web session(基于我们网站)中发现他们的兴趣所在?“数据精炼厂”,这个使用模式正是顾客期望的。
这里的关键概念是Hadoop是被用来提取大量数据以便更容易管理。然后生成的数据被加载到现有数据系统,这些数据可以使用传统的工具访问,但是别忘了,这些操作都是建立在更丰富的数据集上。从某些方面来说,这是最简单的用例,因为无需对传统途径进行大的修改,企业就可以清晰的从Hadoop上获益。无论垂直与否,精炼厂概念仍然适用。在金融服务领域,我们看到组织提炼交易数据以便更好地了解市场,分析和从复杂的组合中寻找价值。能源公司使用大数据来分析不同地区的消费水平以便更好地预测生产水平。零售企业(任何面向消费者组织)经常使用精炼厂来洞察网络人气。电信公司使用精炼厂调用电话记录来提取有用信息细节以便优化计费方式。最后,在昂贵的,任务关键的垂直设备上,我们常常发现Hadoop被用来预测分析和主动的故障识别。在通信技术中,这可能是一个网络的基站。特许经营餐厅中可以用来监控冷藏库的数据。
责编:王雅京
 微信扫一扫实时了解行业动态
微信扫一扫实时了解行业动态
著作权声明:kaiyun体育官方人口 文章著作权分属kaiyun体育官方人口 、网友和合作伙伴,部分非原创文章作者信息可能有所缺失,如需补充或修改请与我们联系,工作人员会在1个工作日内配合处理。
|
最新专题
|

|
|

