|
|
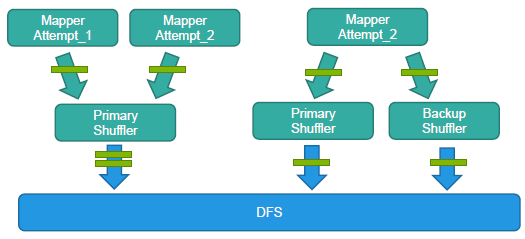
Spark技术解析及在百度开放云BMR应用实践2015年1月10日,一场基于Spark的高性能应用实践盛宴由Databricks软件工程师连城、百度高级工程师甄鹏、百度架构师孙垚光、百度美国研发中心高级架构师刘少山四位专家联手打造。 让New Shuffle模块专注于shuffle,不依赖于外部计算模块,从而计算模块可以专注于计算,同时还避免了磁盘IO。然而New Shuffle带来的问题也随之暴漏,其中影响比较重要的两个就是:慢节点和数据重复。 慢节点。以shuffle写入过程中出现慢节点为例,通常包含两个情况。首先,Shuffle自身慢节点,对比社区版本中只会影响到一个task,New Shuffle中常常会影响到一片集群。在这里,百度为每个Shuffle节点都配置了一个从节点,当Map检测到一个慢节点时,系统会自动切换到从节点。其次,DFS出现慢节点,这个情况下,Shuffle的从节点只能起到缓解作用。这种情况下,首先DFS系统会自动检测出慢节点,并进行替换。比如,传统的HDFS会以pipeline的形式进行写入,而DFS则转换为分发写。 在此之外,New Shuffle还需要解决更多问题,比如资源共享和隔离等。同时,基于New Shuffle的机制,New Shuffle还面临一些其他挑战,比如Reduce全启动、数据过于分散、对DFS压力过大、连接数等等。
数据重复。如上图所示,这些问题主要因为New Shuffle对上层组件缺少感知,这个问题的解决主要使用task id和block id进行去重。 New Shuffle展望 孙垚光表示,New Shuffle使用了通用的Writer和Reader接口,当下已经支持百度MR和DCE(DAG、C++),同时即将对开源Spark提供支持。在未来,New Shuffle无疑将成为更通用的组件,支持更多的计算模型。 百度美国硅谷研发中心高级架构师刘少山——Fast big data analytics with Spark on Tachyon
Tachyon是一个分布式的内存文件系统,可以在集群里以访问内存的速度来访问存在Tachyon里的文件。Tachyon是架构在分布式文件存储和上层各种计算框架之间的中间件,主要负责将那些不需要落到DFS里的文件,落到分布式内存文件系统中,从而达到共享内存,以提高效率。1月10日下午的最后一场分享中,刘少山带来了一场Tachyon的深入解析。 Tachyon和Spark 刘少山表示,在Spark使用过程中,用户经常困扰于3个问题:首先,两个Spark 实例通过存储系统来共享数据,这个过程中对磁盘的操作会显著降低性能;其次,因为Spark崩溃所造成的数据丢失;最后,垃圾回收机制,如果两个Spark实例需求同样的数据,那么这个数据会被缓存两次,从而造成很大的内存压力,更降低性能。
使用Tachyon,存储可以从Spark中分离处理,让其更专注于计算,从而避免了上述的3个问题。 责编:李玉琴  微信扫一扫实时了解行业动态 微信扫一扫实时了解行业动态 著作权声明:kaiyun体育官方人口
文章著作权分属kaiyun体育官方人口
、网友和合作伙伴,部分非原创文章作者信息可能有所缺失,如需补充或修改请与我们联系,工作人员会在1个工作日内配合处理。 |
热门博文 |




|
|

