|
|
Spark技术解析及在百度开放云BMR应用实践2015年1月10日,一场基于Spark的高性能应用实践盛宴由Databricks软件工程师连城、百度高级工程师甄鹏、百度架构师孙垚光、百度美国研发中心高级架构师刘少山四位专家联手打造。
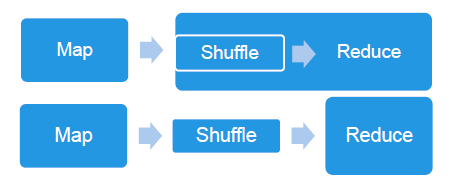
Shuffle简介 孙垚光表示,简单来说,Shuffle就是按照一定的分组和规则Map一个数据,然后传入Reduce端。不管对于MapReduce还是Spark,Shuffle都是一个非常重要的阶段。然而,虽然Shuffle解决的问题相同,但是在Spark和MapReduce中,Shuffle流程(具体时间和细节)仍然存在一定的差别:
Baidu Shuffle发展历程
通过孙垚光了解到,Shuffle在百度的发展主要包括两个阶段:跟随社区和独立发展。从2008年百度的MapReduce/Hadoop起步开始,百度就开始跟随社区,使用社区版本,期间的主要工作包含Bug修复和性能优化两个方面(增加内存池、减少JVMGC,传输Server由Jetty换Netty,及批量传输、聚合数据等方面)。
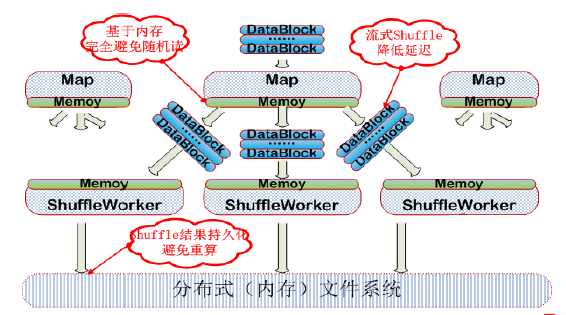
分离了shuffle和Map/Reduce 在2012年开始,Baidu Shuffle开启独立发展阶段,主要源于下一代离线计算系统的开发,Shuffle被抽离为独立的ShuffleService服务,从而提高了集群资源的利用率。 截止此时,不管是社区版本(MapReduce/Spark),还是百度研发的ShuffleService,它们都是基于磁盘的PULL模式。基于磁盘,所有Map的数据都会放到磁盘,虽然Spark号称内存计算,但是涉及到Shuffle时还是会写磁盘。基于PULL,所有数据在放到Map端的磁盘之后,Reduce在使用时还需要主动的拉出来,因此会受到两个问题影响:首先,业务数据存储在Map端的服务器上,机器宕机时会不可避免丢失数据,这一点在大规模分布式集群中非常致命;其次,更重要的是,Shuffle阶段会产生大量的磁盘寻道(随机读)和数据重算(中间数据存在本地磁盘),举个例子,某任务有1百万个Map,1万个Reduce,如果一次磁盘寻道的时间是10毫秒,那么集群总共的磁盘寻道时间= 1000000 ×10000 ×0.01 = 1亿秒。 New Shuffle 基于这些问题,百度设计了基于内存的PUSH模式。新模式下,Map输出的数据将不落磁盘,并在内存中及时地Push给远端的Shuffle模块,从而将获得以下提升:
New Shuffle的优势
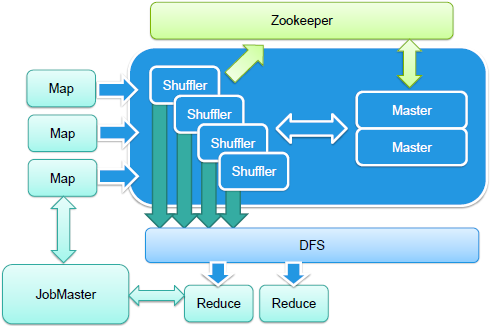
New Shuffle架构 如图所示,蓝色部分为New Shuffle部分,主要包含两个部分:数据写入和读取的API,Map端会使用这个接口来读取数据,Reduce会使用这个接口来读取数据;其次,最终重要的是,服务器端使用了典型的主从架构,用多个shuffle工作者节点来shuffle数据。同时,在系统设计中,Master非常有利于横向扩展,让shuffle不会成为整个分布式系统的瓶颈。 责编:李玉琴  微信扫一扫实时了解行业动态 微信扫一扫实时了解行业动态 著作权声明:kaiyun体育官方人口
文章著作权分属kaiyun体育官方人口
、网友和合作伙伴,部分非原创文章作者信息可能有所缺失,如需补充或修改请与我们联系,工作人员会在1个工作日内配合处理。 |
热门博文 |
.jpg)
.png)



|
|

